설치를 하고…
pip install statsmodels라이브러리를 불러온다. pandas 도 필요하기 때문에 함께 부르자.
from statsmodels.stats.anova import AnovaRM
import pandas as pdpandas 데이터 프레임 형태로 데이터를 준비한다. 각 피험자로부터 얻은 각 실험 조건으로 얻은 데이터가 한 줄이 되는 형태여야 한다. 이걸 long format이라고도 한다. 예를 들면 아래와 같다. 아래 데이터에서 nback과 zone은 실험 데이터 상의 조건(독립변인)이다. scl은 실험에서 얻은 종속 변인이다.
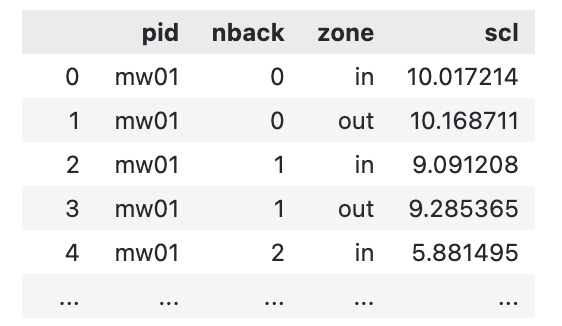
그리고 아래와 같이 입력하면 끝! 위와 같은 실험 데이터를 data 부분에 넣어주고, 실험 참여자를 구분하는 칼럼, 종속 변인 칼럼, 독립 변인 칼럼들을 각각 subject, depvar, within에 넣어준다. RMANOVA 분석을 하는 경우에 독립변인은 참가자 내 요인이기 때문에 파라미터 이름이 within이다. aggregate_func='mean'은 한 사람 내 각 조건에 해당 하는 데이터가 여럿인 경우 평균을 내서 통계 검정을 실시하라는 얘기다.
print(AnovaRM(data=df, depvar='scl', subject='pid', within=['nback', 'zone'],aggregate_func='mean').fit())그럼 아래와 같은 형태의 ANOVA 테이블이 나온다.
Anova
========================================
F Value Num DF Den DF Pr > F
----------------------------------------
nback 2.3272 2.0000 60.0000 0.1063
zone 16.0330 1.0000 30.0000 0.0004
nback:zone 1.0333 2.0000 60.0000 0.3621
========================================이 결과는 ‘간이 결과’다. RM ANOVA분석을 제대로 하려면 Sphericity Assumption을 따르는지 확인하고, 따르지 않는 경우에 통계 분석 값에 대한 보정을 해줘야 하기 때문이다. 다만, 보정한 값과 하지 않은 값이 크게 차이가 나지 않기 때문에, 빠르게 결과를 대강 파악하기에 좋다.